Some methods not included here are available for AVX and AVX2.
If you can not find what you want, please try and change class name from SseX to Avx or Avx2.
Same deal with Vector256/Vector128.
AVX512 is completely missing from .NET Core at this point. To highlight only AVX2 instructions, use this link.
MMX register (64-bit) instructions are omitted.
S1=SSE S2=SSE2 S3=SSE3 SS3=SSSE3 S4.1=SSE4.1 S4.2=SSE4.2 V1=AVX
V2=AVX2 V5=AVX512
Instructions marked * become scalar instructions (only the lowest element is calculated) when PS/PD/DQ is changed to SS/SD/SI.
This document is intended that you can find the correct instruction name that you are not sure of, and make it possible to search in the manuals. Refer to the manuals before coding.
| |
Integer |
Floating-Point |
YMM lane (128-bit) |
| QWORD |
DWORD |
WORD |
BYTE |
Double |
Single |
Half |
?MM whole

?MM/mem
|
MOVDQA (S2
_mm_load_si128
Sse2.LoadAlignedVector128 ♯
_mm_store_si128
Sse2.StoreAligned ♯
MOVDQU (S2
_mm_loadu_si128
Sse2.LoadVector128 ♯
_mm_storeu_si128
Sse2.Store ♯
|
MOVAPD (S2
_mm_load_pd
Sse2.LoadAlignedVector128 ♯
_mm_loadr_pd
_mm_store_pd
Sse2.StoreAligned ♯
_mm_storer_pd
MOVUPD (S2
_mm_loadu_pd
Sse2.LoadVector128 ♯
_mm_storeu_pd
Sse2.Store ♯
|
MOVAPS (S1
_mm_load_ps
Sse.LoadAlignedVector128 ♯
_mm_loadr_ps
_mm_store_ps
Sse.StoreAligned ♯
_mm_storer_ps
MOVUPS (S1
_mm_loadu_ps
Sse.LoadVector128 ♯
_mm_storeu_ps
Sse.Store ♯
|
|
|
VMOVDQA64 (V5...
_mm_mask_load_epi64
_mm_mask_store_epi64
etc
VMOVDQU64 (V5...
_mm_mask_loadu_epi64
_mm_mask_store_epi64
etc
|
VMOVDQA32 (V5...
_mm_mask_load_epi32
_mm_mask_store_epi32
etc
VMOVDQU32 (V5...
_mm_mask_loadu_epi32
_mm_mask_storeu_epi32
etc
|
VMOVDQU16 (V5+BW...
_mm_mask_loadu_epi16
_mm_mask_storeu_epi16
etc
|
VMOVDQU8 (V5+BW...
_mm_mask_loadu_epi8
_mm_mask_storeu_epi8
etc
|
XMM upper half
mem
|
|
|
|
|
MOVHPD (S2
_mm_loadh_pd
Sse2.LoadHigh ♯
_mm_storeh_pd
Sse2.StoreHigh ♯
|
MOVHPS (S1
_mm_loadh_pi
Sse.LoadHigh ♯
_mm_storeh_pi
Sse.StoreHigh ♯
|
|
|
XMM upper half
XMM lower half
|
|
|
|
|
|
MOVHLPS (S1
_mm_movehl_ps
Sse.MoveHighToLow ♯
MOVLHPS (S1
_mm_movelh_ps
Sse.MoveLowToHigh ♯
|
|
|
XMM lower half
mem
|
MOVQ (S2
_mm_loadl_epi64
Sse2.LoadScalarVector128 ♯
_mm_storel_epi64
Sse2.StoreScalar ♯
|
|
|
|
MOVLPD (S2
_mm_loadl_pd
Sse2.LoadLow ♯
_mm_storel_pd
Sse2.StoreLow ♯
|
MOVLPS (S1
_mm_loadl_pi
Sse.LoadLow ♯
_mm_storel_pi
Sse.StoreLow ♯
|
|
|
XMM lowest 1 elem
r/m
|
MOVQ (S2
_mm_cvtsi64_si128
Sse2.X64.ConvertScalarToVector128Int64 ♯
Sse2.X64.ConvertScalarToVector128UInt64 ♯
_mm_cvtsi128_si64
Sse2.X64.ConvertToInt64 ♯
Sse2.X64.ConvertToUInt64 ♯
|
MOVD (S2
_mm_cvtsi32_si128
Sse2.ConvertScalarToVector128Int32 ♯
Sse2.ConvertScalarToVector128UInt32 ♯
_mm_cvtsi128_si32
Sse2.ConvertToInt32 ♯
Sse2.ConvertToUInt32 ♯
|
|
|
|
|
|
|
XMM lowest 1 elem
XMM/mem
|
MOVQ (S2
_mm_move_epi64
Sse2.MoveScalar ♯
|
|
|
|
MOVSD (S2
_mm_load_sd
Sse2.LoadScalarVector128 ♯
_mm_store_sd
Sse2.StoreScalar ♯
_mm_move_sd
Sse2.MoveScalar ♯
|
MOVSS (S1
_mm_load_ss
Sse.LoadScalarVector128 ♯
_mm_store_ss
Sse.StoreScalar ♯
_mm_move_ss
Sse.MoveScalar ♯
|
|
|
XMM whole

1 elem
|
TIP 2
_mm_set1_epi64x
VPBROADCASTQ (V2
_mm_broadcastq_epi64
Avx2.BroadcastScalarToVector128 ♯
|
TIP 2
_mm_set1_epi32
VPBROADCASTD (V2
_mm_broadcastd_epi32
Avx2.BroadcastScalarToVector128 ♯
|
TIP 2
_mm_set1_epi16
VPBROADCASTW (V2
_mm_broadcastw_epi16
Avx2.BroadcastScalarToVector128 ♯
|
_mm_set1_epi8
VPBROADCASTB (V2
_mm_broadcastb_epi8
Avx2.BroadcastScalarToVector128 ♯
|
TIP 2
_mm_set1_pd
_mm_load1_pd
MOVDDUP (S3
_mm_movedup_pd
Sse3.MoveAndDuplicate ♯
_mm_loaddup_pd
Sse3.LoadAndDuplicateToVector128 ♯
|
TIP 2
_mm_set1_ps
_mm_load1_ps
VBROADCASTSS
from mem (V1
from XMM (V2
_mm_broadcast_ss
Avx.BroadcastScalarToVector128 ♯
|
|
|
YMM / ZMM whole
1 elem
|
VPBROADCASTQ (V2
_mm256_broadcastq_epi64
Avx2.BroadcastScalarToVector256 ♯
|
VPBROADCASTD (V2
_mm256_broadcastd_epi32
Avx2.BroadcastScalarToVector256 ♯
|
VPBROADCASTW (V2
_mm256_broadcastw_epi16
Avx2.BroadcastScalarToVector256 ♯
|
VPBROADCASTB (V2
_mm256_broadcastb_epi8
Avx2.BroadcastScalarToVector256 ♯
|
VBROADCASTSD
from mem (V1
from XMM (V2
_mm256_broadcast_sd
Avx.BroadcastScalarToVector256 ♯
|
VBROADCASTSS
from mem (V1
from XMM (V2
_mm256_broadcast_ss
Avx.BroadcastScalarToVector256 ♯
|
|
VBROADCASTF128 (V1
_mm256_broadcast_ps
Avx.BroadcastVector128ToVector256 ♯
_mm256_broadcast_pd
Avx.BroadcastVector128ToVector256 ♯
VBROADCASTI128 (V2
_mm256_broadcastsi128_si256
Avx2.BroadcastVector128ToVector256 ♯
|
YMM / ZMM whole
2/4/8 elems
|
VBROADCASTI64X2 (V5+DQ...
_mm512_broadcast_i64x2
VBROADCASTI64X4 (V5
_mm512_broadcast_i64x4
|
VBROADCASTI32X2 (V5+DQ...
_mm512_broadcast_i32x2
VBROADCASTI32X4 (V5...
_mm512_broadcast_i32x4
VBROADCASTI32X8 (V5+DQ
_mm512_broadcast_i32x8
|
|
|
VBROADCASTF64X2 (V5+DQ...
_mm512_broadcast_f64x2
VBROADCASTF64X4 (V5
_mm512_broadcast_f64x4
|
VBROADCASTF32X2 (V5+DQ...
_mm512_broadcast_f32x2
VBROADCASTF32X4 (V5...
_mm512_broadcast_f32x4
VBROADCASTF32X8 (V5+DQ
_mm512_broadcast_f32x8
|
|
|
?MM
multiple elems
|
_mm_set_epi64x
Vector256.Create ♯
_mm_setr_epi64x
|
_mm_set_epi32
Vector256.Create ♯
_mm_setr_epi32
|
_mm_set_epi16
Vector256.Create ♯
_mm_setr_epi16
|
_mm_set_epi8
Vector256.Create ♯
_mm_setr_epi8
|
_mm_set_pd
Vector256.Create ♯
_mm_setr_pd
|
_mm_set_ps
Vector256.Create ♯
_mm_setr_ps
|
|
|
?MM whole
zero
|
TIP 1
_mm_setzero_si128
Vector256`1.Zero ♯
|
TIP 1
_mm_setzero_pd
Vector256`1.Zero ♯
|
TIP 1
_mm_setzero_ps
Vector256`1.Zero ♯
|
|
|
| extract |
PEXTRQ (S4.1
_mm_extract_epi64
Sse41.X64.Extract ♯
|
PEXTRD (S4.1
_mm_extract_epi32
Sse41.Extract ♯
|
PEXTRW to r (S2
PEXTRW to r/m (S4.1
_mm_extract_epi16
Sse2.Extract ♯
|
PEXTRB (S4.1
_mm_extract_epi8
Sse41.Extract ♯
|
->MOVHPD (S2
_mm_loadh_pd
Sse2.LoadHigh ♯
_mm_storeh_pd
Sse2.StoreHigh ♯
->MOVLPD (S2
_mm_loadl_pd
Sse2.LoadLow ♯
_mm_storel_pd
Sse2.StoreLow ♯
|
EXTRACTPS (S4.1
_mm_extract_ps
Sse41.Extract ♯
|
|
VEXTRACTF128 (V1
_mm256_extractf128_ps
Avx.ExtractVector128 ♯
_mm256_extractf128_pd
Avx.ExtractVector128 ♯
_mm256_extractf128_si256
Avx.ExtractVector128 ♯
VEXTRACTI128 (V2
_mm256_extracti128_si256
Avx2.ExtractVector128 ♯
|
VEXTRACTI64X2 (V5+DQ...
_mm512_extracti64x2_epi64
VEXTRACTI64X4 (V5
_mm512_extracti64x4_epi64
|
VEXTRACTI32X4 (V5...
_mm512_extracti32x4_epi32
VEXTRACTI32X8 (V5+DQ
_mm512_extracti32x8_epi32
|
|
|
VEXTRACTF64X2 (V5+DQ...
_mm512_extractf64x2_pd
VEXTRACTF64X4 (V5
_mm512_extractf64x4_pd
|
VEXTRACTF32X4 (V5...
_mm512_extractf32x4_ps
VEXTRACTF32X8 (V5+DQ
_mm512_extractf32x8_ps
|
|
|
| insert |
PINSRQ (S4.1
_mm_insert_epi64
Sse41.X64.Insert ♯
|
PINSRD (S4.1
_mm_insert_epi32
Sse41.Insert ♯
|
PINSRW (S2
_mm_insert_epi16
Sse2.Insert ♯
|
PINSRB (S4.1
_mm_insert_epi8
Sse41.Insert ♯
|
->MOVHPD (S2
_mm_loadh_pd
Sse2.LoadHigh ♯
_mm_storeh_pd
Sse2.StoreHigh ♯
->MOVLPD (S2
_mm_loadl_pd
Sse2.LoadLow ♯
_mm_storel_pd
Sse2.StoreLow ♯
|
INSERTPS (S4.1
_mm_insert_ps
Sse41.Insert ♯
|
|
VINSERTF128 (V1
_mm256_insertf128_ps
Avx.InsertVector128 ♯
_mm256_insertf128_pd
Avx.InsertVector128 ♯
_mm256_insertf128_si256
Avx.InsertVector128 ♯
VINSERTI128 (V2
_mm256_inserti128_si256
Avx2.InsertVector128 ♯
|
VINSERTI64X2 (V5+DQ...
_mm512_inserrti64x2
VINSERTI64X4 (V5...
_mm512_inserti64x4
|
VINSERTI32X4 (V5...
_mm512_inserti32x4
VINSERTI32X8 (V5+DQ
_mm512_inserti32x8
|
|
|
VINSERTF64X2 (V5+DQ...
_mm512_insertf64x2
VINSERTF64X4 (V5
_mm512_insertf64x4
|
VINSERTF32X4 (V5...
_mm512_insertf32x4
VINSERTF32X8 (V5+DQ
_mm512_insertf32x8
|
|
|
unpack
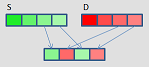 |
PUNPCKHQDQ (S2
_mm_unpackhi_epi64
Sse2.UnpackHigh ♯
PUNPCKLQDQ (S2
_mm_unpacklo_epi64
Sse2.UnpackLow ♯
|
PUNPCKHDQ (S2
_mm_unpackhi_epi32
Sse2.UnpackHigh ♯
PUNPCKLDQ (S2
_mm_unpacklo_epi32
Sse2.UnpackLow ♯
|
PUNPCKHWD (S2
_mm_unpackhi_epi16
Sse2.UnpackHigh ♯
PUNPCKLWD (S2
_mm_unpacklo_epi16
Sse2.UnpackLow ♯
|
PUNPCKHBW (S2
_mm_unpackhi_epi8
Sse2.UnpackHigh ♯
PUNPCKLBW (S2
_mm_unpacklo_epi8
Sse2.UnpackLow ♯
|
UNPCKHPD (S2
_mm_unpackhi_pd
Sse2.UnpackHigh ♯
UNPCKLPD (S2
_mm_unpacklo_pd
Sse2.UnpackLow ♯
|
UNPCKHPS (S1
_mm_unpackhi_ps
Sse.UnpackHigh ♯
UNPCKLPS (S1
_mm_unpacklo_ps
Sse.UnpackLow ♯
|
|
|
shuffle/permute
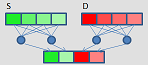
|
VPERMQ (V2
_mm256_permute4x64_epi64
Avx2.Permute4x64 ♯
VPERMI2Q (V5...
_mm_permutex2var_epi64
|
PSHUFD (S2
_mm_shuffle_epi32
Sse2.Shuffle ♯
VPERMD (V2
_mm256_permutevar8x32_epi32
Avx2.PermuteVar8x32 ♯
_mm256_permutexvar_epi32
VPERMI2D (V5...
_mm_permutex2var_epi32
|
PSHUFHW (S2
_mm_shufflehi_epi16
Sse2.ShuffleHigh ♯
PSHUFLW (S2
_mm_shufflelo_epi16
Sse2.ShuffleLow ♯
VPERMW (V5+BW...
_mm_permutexvar_epi16
VPERMI2W (V5+BW...
_mm_permutex2var_epi16
|
PSHUFB (SS3
_mm_shuffle_epi8
Ssse3.Shuffle ♯
|
SHUFPD (S2
_mm_shuffle_pd
Sse2.Shuffle ♯
VPERMILPD (V1
_mm_permute_pd
Avx.Permute ♯
_mm_permutevar_pd
Avx.PermuteVar ♯
VPERMPD (V2
_mm256_permute4x64_pd
Avx2.Permute4x64 ♯
VPERMI2PD (V5...
_mm_permutex2var_pd
|
SHUFPS (S1
_mm_shuffle_ps
Sse.Shuffle ♯
VPERMILPS (V1
_mm_permute_ps
Avx.Permute ♯
_mm_permutevar_ps
Avx.PermuteVar ♯
VPERMPS (V2
_mm256_permutevar8x32_ps
Avx2.PermuteVar8x32 ♯
VPERMI2PS (V5...
_mm_permutex2var_ps
|
|
VPERM2F128 (V1
_mm256_permute2f128_ps
Avx.Permute2x128 ♯
_mm256_permute2f128_pd
Avx.Permute2x128 ♯
_mm256_permute2f128_si256
Avx.Permute2x128 ♯
VPERM2I128 (V2
_mm256_permute2x128_si256
Avx2.Permute2x128 ♯
|
VSHUFI64X2 (V5...
_mm512_shuffle_i64x2
|
VSHUFI32X4 (V5...
_mm512_shuffle_i32x4
|
|
|
VSHUFF64X2 (V5...
_mm512_shuffle_f64x2
|
VSHUFF32X4 (V5...
_mm512_shuffle_f32x4
|
|
|
blend
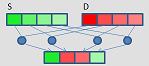
|
VPBLENDMQ (V5...
_mm_mask_blend_epi32
|
VPBLENDD (V2
_mm_blend_epi32
Avx2.Blend ♯
VPBLENDMD (V5...
_mm_mask_blend_epi32
|
PBLENDW (S4.1
_mm_blend_epi16
Sse41.Blend ♯
VPBLENDMW (V5+BW...
_mm_mask_blend_epi16
|
PBLENDVB (S4.1
_mm_blendv_epi8
Sse41.BlendVariable ♯
VPBLENDMB (V5+BW...
_mm_mask_blend_epi8
|
BLENDPD (S4.1
_mm_blend_pd
Sse41.Blend ♯
BLENDVPD (S4.1
_mm_blendv_pd
Sse41.BlendVariable ♯
VBLENDMPD (V5...
_mm_mask_blend_pd
|
BLENDPS (S4.1
_mm_blend_ps
Sse41.Blend ♯
BLENDVPS (S4.1
_mm_blendv_ps
Sse41.BlendVariable ♯
VBLENDMPS (V5...
_mm_mask_blend_ps
|
|
|
| move and duplicate |
|
|
|
|
MOVDDUP (S3
_mm_movedup_pd
Sse3.MoveAndDuplicate ♯
_mm_loaddup_pd
Sse3.LoadAndDuplicateToVector128 ♯
|
MOVSHDUP (S3
_mm_movehdup_ps
Sse3.MoveHighAndDuplicate ♯
MOVSLDUP (S3
_mm_moveldup_ps
Sse3.MoveLowAndDuplicate ♯
|
|
|
| mask move |
VPMASKMOVQ (V2
_mm_maskload_epi64
Avx2.MaskLoad ♯
_mm_maskstore_epi64
Avx2.MaskStore ♯
|
VPMASKMOVD (V2
_mm_maskload_epi32
Avx2.MaskLoad ♯
_mm_maskstore_epi32
Avx2.MaskStore ♯
|
|
|
VMASKMOVPD (V1
_mm_maskload_pd
Avx.MaskLoad ♯
_mm_maskstore_pd
Avx.MaskStore ♯
|
VMASKMOVPS (V1
_mm_maskload_ps
Avx.MaskLoad ♯
_mm_maskstore_ps
Avx.MaskStore ♯
|
|
|
| extract highest bit |
|
|
|
PMOVMSKB (S2
_mm_movemask_epi8
Sse2.MoveMask ♯
|
MOVMSKPD (S2
_mm_movemask_pd
Sse2.MoveMask ♯
|
MOVMSKPS (S1
_mm_movemask_ps
Sse.MoveMask ♯
|
|
|
VPMOVQ2M (V5+DQ...
_mm_movepi64_mask
|
VPMOVD2M (V5+DQ...
_mm_movepi32_mask
|
VPMOVW2M (V5+BW...
_mm_movepi16_mask
|
VPMOVB2M (V5+BW...
_mm_movepi8_mask
|
|
|
|
|
gather
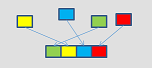 |
VPGATHERDQ (V2
_mm_i32gather_epi64
Avx2.GatherVector128 ♯
_mm_mask_i32gather_epi64
Avx2.GatherMaskVector128 ♯
VPGATHERQQ (V2
_mm_i64gather_epi64
Avx2.GatherVector128 ♯
_mm_mask_i64gather_epi64
Avx2.GatherMaskVector128 ♯
|
VPGATHERDD (V2
_mm_i32gather_epi32
Avx2.GatherVector128 ♯
_mm_mask_i32gather_epi32
Avx2.GatherMaskVector128 ♯
VPGATHERQD (V2
_mm_i64gather_epi32
Avx2.GatherVector128 ♯
_mm_mask_i64gather_epi32
Avx2.GatherMaskVector128 ♯
|
|
|
VGATHERDPD (V2
_mm_i32gather_pd
Avx2.GatherVector128 ♯
_mm_mask_i32gather_pd
Avx2.GatherMaskVector128 ♯
VGATHERQPD (V2
_mm_i64gather_pd
Avx2.GatherVector128 ♯
_mm_mask_i64gather_pd
Avx2.GatherMaskVector128 ♯
|
VGATHERDPS (V2
_mm_i32gather_ps
Avx2.GatherVector128 ♯
_mm_mask_i32gather_ps
Avx2.GatherMaskVector128 ♯
VGATHERQPS (V2
_mm_i64gather_ps
Avx2.GatherVector128 ♯
_mm_mask_i64gather_ps
Avx2.GatherMaskVector128 ♯
|
|
|
scatter
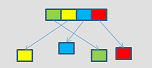 |
VPSCATTERDQ (V5...
_mm_i32scatter_epi64
_mm_mask_i32scatter_epi64
VPSCATTERQQ (V5...
_mm_i64scatter_epi64
_mm_mask_i64scatter_epi64
|
VPSCATTERDD (V5...
_mm_i32scatter_epi32
_mm_mask_i32scatter_epi32
VPSCATTERQD (V5...
_mm_i64scatter_epi32
_mm_mask_i64scatter_epi32
|
|
|
VSCATTERDPD (V5...
_mm_i32scatter_pd
_mm_mask_i32scatter_pd
VSCATTERQPD (V5...
_mm_i64scatter_pd
_mm_mask_i64scatter_pd
|
VSCATTERDPS (V5...
_mm_i32scatter_ps
_mm_mask_i32scatter_ps
VSCATTERQPS (V5...
_mm_i64scatter_ps
_mm_mask_i64scatter_ps
|
|
|
compress
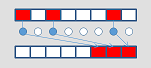 |
VPCOMPRESSQ (V5...
_mm_mask_compress_epi64
_mm_mask_compressstoreu_epi64
|
VPCOMPRESSD (V5...
_mm_mask_compress_epi32
_mm_mask_compressstoreu_epi32
|
|
|
VCOMPRESSPD (V5...
_mm_mask_compress_pd
_mm_mask_compressstoreu_pd
|
VCOMPRESSPS (V5...
_mm_mask_compress_ps
_mm_mask_compressstoreu_ps
|
|
|
expand
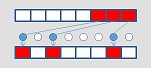 |
VEXPANDQ (V5...
_mm_mask_expand_epi64
_mm_mask_expandloadu_epi64
|
VEXPANDD (V5...
_mm_mask_expand_epi32
_mm_mask_expandloadu_epi32
|
|
|
VEXPANDPD (V5...
_mm_mask_expand_pd
_mm_mask_expandloadu_pd
|
VEXPANDPS (V5...
_mm_mask_expand_ps
_mm_mask_expandloadu_ps
|
|
|
| align right |
VALIGNQ (V5...
_mm_alignr_epi64
|
VALIGND (V5...
_mm_alignr_epi32
|
|
PALIGNR (SS3
_mm_alignr_epi8
Ssse3.AlignRight ♯
|
|
|
|
|
| expand Opmask bits |
VPMOVM2Q (V5+DQ...
_mm_movm_epi64
|
VPMOVM2D (V5+DQ...
_mm_movm_epi32
|
VPMOVM2W (V5+BW...
_mm_movm_epi16
|
VPMOVM2B (V5+BW...
_mm_movm_epi8
|
|
|
|
|
| from \ to |
Integer |
Floating-Point |
| QWORD |
DWORD |
WORD |
BYTE |
Double |
Single |
Half |
| Integer |
QWORD |
|
VPMOVQD (V5...
_mm_cvtepi64_epi32
VPMOVSQD (V5...
_mm_cvtsepi64_epi32
VPMOVUSQD (V5...
_mm_cvtusepi64_epi32
|
VPMOVQW (V5...
_mm_cvtepi64_epi16
VPMOVSQW (V5...
_mm_cvtsepi64_epi16
VPMOVUSQW (V5...
_mm_cvtusepi64_epi16
|
VPMOVQB (V5...
_mm_cvtepi64_epi8
VPMOVSQB (V5...
_mm_cvtsepi64_epi8
VPMOVUSQB (V5...
_mm_cvtusepi64_epi8
|
CVTSI2SD (S2 scalar only
_mm_cvtsi64_sd
Sse2.X64.ConvertScalarToVector128Double ♯
VCVTQQ2PD* (V5+DQ...
_mm_cvtepi64_pd
VCVTUQQ2PD* (V5+DQ...
_mm_cvtepu64_pd
|
CVTSI2SS (S1 scalar only
_mm_cvtsi64_ss
Sse.X64.ConvertScalarToVector128Single ♯
VCVTQQ2PS* (V5+DQ...
_mm_cvtepi64_ps
VCVTUQQ2PS* (V5+DQ...
_mm_cvtepu64_ps
|
|
| DWORD |
TIP 3
PMOVSXDQ (S4.1
_mm_ cvtepi32_epi64
Sse41.ConvertToVector128Int64 ♯
PMOVZXDQ (S4.1
_mm_ cvtepu32_epi64
Sse41.ConvertToVector128Int64 ♯
|
|
PACKSSDW (S2
_mm_packs_epi32
Sse2.PackSignedSaturate ♯
PACKUSDW (S4.1
_mm_packus_epi32
Sse41.PackUnsignedSaturate ♯
VPMOVDW (V5...
_mm_cvtepi32_epi16
VPMOVSDW (V5...
_mm_cvtsepi32_epi16
VPMOVUSDW (V5...
_mm_cvtusepi32_epi16
|
VPMOVDB (V5...
_mm_cvtepi32_epi8
VPMOVSDB (V5...
_mm_cvtsepi32_epi8
VPMOVUSDB (V5...
_mm_cvtusepi32_epi8
|
CVTDQ2PD* (S2
_mm_cvtepi32_pd
Sse2.ConvertToVector128Double ♯
VCVTUDQ2PD* (V5...
_mm_cvtepu32_pd
|
CVTDQ2PS* (S2
_mm_cvtepi32_ps
Sse2.ConvertToVector128Single ♯
VCVTUDQ2PS* (V5...
_mm_cvtepu32_ps
|
|
| WORD |
PMOVSXWQ (S4.1
_mm_ cvtepi16_epi64
Sse41.ConvertToVector128Int64 ♯
PMOVZXWQ (S4.1
_mm_ cvtepu16_epi64
Sse41.ConvertToVector128Int64 ♯
|
TIP 3
PMOVSXWD (S4.1
_mm_ cvtepi16_epi32
Sse41.ConvertToVector128Int32 ♯
PMOVZXWD (S4.1
_mm_ cvtepu16_epi32
Sse41.ConvertToVector128Int32 ♯
|
|
PACKSSWB (S2
_mm_packs_epi16
Sse2.PackSignedSaturate ♯
PACKUSWB (S2
_mm_packus_epi16
Sse2.PackUnsignedSaturate ♯
VPMOVWB (V5+BW...
_mm_cvtepi16_epi8
VPMOVSWB (V5+BW...
_mm_cvtsepi16_epi8
VPMOVUSWB (V5+BW...
_mm_cvtusepi16_epi8
|
|
|
|
| BYTE |
PMOVSXBQ (S4.1
_mm_ cvtepi8_epi64
Sse41.ConvertToVector128Int64 ♯
PMOVZXBQ (S4.1
_mm_ cvtepu8_epi64
Sse41.ConvertToVector128Int64 ♯
|
PMOVSXBD (S4.1
_mm_ cvtepi8_epi32
Sse41.ConvertToVector128Int32 ♯
PMOVZXBD (S4.1
_mm_ cvtepu8_epi32
Sse41.ConvertToVector128Int32 ♯
|
TIP 3
PMOVSXBW (S4.1
_mm_ cvtepi8_epi16
Sse41.ConvertToVector128Int16 ♯
PMOVZXBW (S4.1
_mm_ cvtepu8_epi16
Sse41.ConvertToVector128Int16 ♯
|
|
|
|
|
| Floating-Point |
Double |
CVTSD2SI /
CVTTSD2SI (S2 scalar only
_mm_cvtsd_si64 / _mm_cvttsd_si64
Sse2.X64.ConvertToInt64 ♯ / Sse2.X64.ConvertToInt64WithTruncation ♯
VCVTPD2QQ* /
VCVTTPD2QQ* (V5+DQ...
_mm_cvtpd_epi64 / _mm_cvttpd_epi64
VCVTPD2UQQ* /
VCVTTPD2UQQ* (V5+DQ...
_mm_cvtpd_epu64 / _mm_cvttpd_epu64
right ones are with truncation
|
CVTPD2DQ* /
CVTTPD2DQ* (S2
_mm_cvtpd_epi32 / _mm_cvttpd_epi32
Sse2.ConvertToVector128Int32 ♯ / Sse2.ConvertToVector128Int32WithTruncation ♯
VCVTPD2UDQ* /
VCVTTPD2UDQ* (V5...
_mm_cvtpd_epu32 / _mm_cvttpd_epu32
right ones are with truncation
|
|
|
|
CVTPD2PS* (S2
_mm_cvtpd_ps
Sse2.ConvertToVector128Single ♯
|
|
| Single |
CVTSS2SI /
CVTTSS2SI (S1 scalar only
_mm_cvtss_si64 / _mm_cvttss_si64
Sse.X64.ConvertToInt64 ♯ / Sse.X64.ConvertToInt64WithTruncation ♯
VCVTPS2QQ* /
VCVTTPS2QQ* (V5+DQ...
_mm_cvtps_epi64 / _mm_cvttps_epi64
VCVTPS2UQQ* /
VCVTTPS2UQQ* (V5+DQ...
_mm_cvtps_epu64 / _mm_cvttps_epu64
right ones are with truncation
|
CVTPS2DQ* /
CVTTPS2DQ* (S2
_mm_cvtps_epi32 / _mm_cvttps_epi32
Sse2.ConvertToVector128Int32 ♯ / Sse2.ConvertToVector128Int32WithTruncation ♯
VCVTPS2UDQ* /
VCVTTPS2UDQ* (V5...
_mm_cvtps_epu32 / _mm_cvttps_epu32
right ones are with truncation
|
|
|
CVTPS2PD* (S2
_mm_cvtps_pd
Sse2.ConvertToVector128Double ♯
|
|
VCVTPS2PH (F16C
_mm_cvtps_ph
|
| Half |
|
|
|
|
|
VCVTPH2PS (F16C
_mm_cvtph_ps
|
|
| |
Integer |
Floating-Point |
| QWORD |
DWORD |
WORD |
BYTE |
Double |
Single |
Half |
| add |
PADDQ (S2
_mm_add_epi64
Sse2.Add ♯
|
PADDD (S2
_mm_add_epi32
Sse2.Add ♯
|
PADDW (S2
_mm_add_epi16
Sse2.Add ♯
PADDSW (S2
_mm_adds_epi16
Sse2.AddSaturate ♯
PADDUSW (S2
_mm_adds_epu16
Sse2.AddSaturate ♯
|
PADDB (S2
_mm_add_epi8
Sse2.Add ♯
PADDSB (S2
_mm_adds_epi8
Sse2.AddSaturate ♯
PADDUSB (S2
_mm_adds_epu8
Sse2.AddSaturate ♯
|
ADDPD* (S2
_mm_add_pd
Sse2.Add ♯
|
ADDPS* (S1
_mm_add_ps
Sse.Add ♯
|
|
| sub |
PSUBQ (S2
_mm_sub_epi64
Sse2.Subtract ♯
|
PSUBD (S2
_mm_sub_epi32
Sse2.Subtract ♯
|
PSUBW (S2
_mm_sub_epi16
Sse2.Subtract ♯
PSUBSW (S2
_mm_subs_epi16
Sse2.SubtractSaturate ♯
PSUBUSW (S2
_mm_subs_epu16
Sse2.SubtractSaturate ♯
|
PSUBB (S2
_mm_sub_epi8
Sse2.Subtract ♯
PSUBSB (S2
_mm_subs_epi8
Sse2.SubtractSaturate ♯
PSUBUSB (S2
_mm_subs_epu8
Sse2.SubtractSaturate ♯
|
SUBPD* (S2
_mm_sub_pd
Sse2.Subtract ♯
|
SUBPS* (S1
_mm_sub_ps
Sse.Subtract ♯
|
|
| mul |
VPMULLQ (V5+DQ...
_mm_mullo_epi64
|
PMULDQ (S4.1
_mm_mul_epi32
Sse41.Multiply ♯
PMULUDQ (S2
_mm_mul_epu32
Sse2.Multiply ♯
PMULLD (S4.1
_mm_mullo_epi32
Sse41.MultiplyLow ♯
|
PMULHW (S2
_mm_mulhi_epi16
Sse2.MultiplyHigh ♯
PMULHUW (S2
_mm_mulhi_epu16
Sse2.MultiplyHigh ♯
PMULLW (S2
_mm_mullo_epi16
Sse2.MultiplyLow ♯
|
|
MULPD* (S2
_mm_mul_pd
Sse2.Multiply ♯
|
MULPS* (S1
_mm_mul_ps
Sse.Multiply ♯
|
|
| div |
|
|
|
|
DIVPD* (S2
_mm_div_pd
Sse2.Divide ♯
|
DIVPS* (S1
_mm_div_ps
Sse.Divide ♯
|
|
| reciprocal |
|
|
|
|
VRCP14PD* (V5...
_mm_rcp14_pd
VRCP28PD* (V5+ER
_mm512_rcp28_pd
|
RCPPS* (S1
_mm_rcp_ps
Sse.Reciprocal ♯
VRCP14PS* (V5...
_mm_rcp14_ps
VRCP28PS* (V5+ER
_mm512_rcp28_ps
|
|
| square root |
|
|
|
|
SQRTPD* (S2
_mm_sqrt_pd
Sse2.Sqrt ♯
|
SQRTPS* (S1
_mm_sqrt_ps
Sse.Sqrt ♯
|
|
| reciprocal of square root |
|
|
|
|
VRSQRT14PD* (V5...
_mm_rsqrt14_pd
VRSQRT28PD* (V5+ER
_mm512_rsqrt28_pd
|
RSQRTPS* (S1
_mm_rsqrt_ps
Sse.ReciprocalSqrt ♯
VRSQRT14PS* (V5...
_mm_rsqrt14_ps
VRSQRT28PS* (V5+ER
_mm_rsqrt28_ps
|
|
| power of two |
|
|
|
|
VEXP2PD* (V5+ER
_mm512_exp2a23_roundpd
|
VEXP2PS* (V5+ER
_mm512_exp2a23_round_ps
|
|
| multiply nth power of 2 |
|
|
|
|
VSCALEFPD* (V5...
_mm_scalef_pd
|
VSCALEFPS* (V5...
_mm_scalef_ps
|
|
| max |
TIP 8
VPMAXSQ (V5...
_mm_max_epi64
VPMAXUQ (V5...
_mm_max_epu64
|
TIP 8
PMAXSD (S4.1
_mm_max_epi32
Sse41.Max ♯
PMAXUD (S4.1
_mm_max_epu32
Sse41.Max ♯
|
PMAXSW (S2
_mm_max_epi16
Sse2.Max ♯
PMAXUW (S4.1
_mm_max_epu16
Sse41.Max ♯
|
TIP 8
PMAXSB (S4.1
_mm_max_epi8
Sse41.Max ♯
PMAXUB (S2
_mm_max_epu8
Sse2.Max ♯
|
TIP 8
MAXPD* (S2
_mm_max_pd
Sse2.Max ♯
|
TIP 8
MAXPS* (S1
_mm_max_ps
Sse.Max ♯
|
|
| min |
TIP 8
VPMINSQ (V5...
_mm_min_epi64
VPMINUQ (V5...
_mm_min_epu64
|
TIP 8
PMINSD (S4.1
_mm_min_epi32
Sse41.Min ♯
PMINUD (S4.1
_mm_min_epu32
Sse41.Min ♯
|
PMINSW (S2
_mm_min_epi16
Sse2.Min ♯
PMINUW (S4.1
_mm_min_epu16
Sse41.Min ♯
|
TIP 8
PMINSB (S4.1
_mm_min_epi8
Sse41.Min ♯
PMINUB (S2
_mm_min_epu8
Sse2.Min ♯
|
TIP 8
MINPD* (S2
_mm_min_pd
Sse2.Min ♯
|
TIP 8
MINPS* (S1
_mm_min_ps
Sse.Min ♯
|
|
| average |
|
|
PAVGW (S2
_mm_avg_epu16
Sse2.Average ♯
|
PAVGB (S2
_mm_avg_epu8
Sse2.Average ♯
|
|
|
|
| absolute |
TIP 4
VPABSQ (V5...
_mm_abs_epi64
|
TIP 4
PABSD (SS3
_mm_abs_epi32
Ssse3.Abs ♯
|
TIP 4
PABSW (SS3
_mm_abs_epi16
Ssse3.Abs ♯
|
TIP 4
PABSB (SS3
_mm_abs_epi8
Ssse3.Abs ♯
|
TIP 5 |
TIP 5 |
|
| sign operation |
|
PSIGND (SS3
_mm_sign_epi32
Ssse3.Sign ♯
|
PSIGNW (SS3
_mm_sign_epi16
Ssse3.Sign ♯
|
PSIGNB (SS3
_mm_sign_epi8
Ssse3.Sign ♯
|
|
|
|
| round |
|
|
|
|
ROUNDPD* (S4.1
_mm_round_pd
Sse41.RoundToNearestInteger ♯
_mm_floor_pd
Sse41.Floor ♯
_mm_ceil_pd
Sse41.Ceiling ♯
VRNDSCALEPD* (V5...
_mm_roundscale_pd
|
ROUNDPS* (S4.1
_mm_round_ps
Sse41.RoundToNearestInteger ♯
_mm_floor_ps
Sse41.Floor ♯
_mm_ceil_ps
Sse41.Ceiling ♯
VRNDSCALEPS* (V5...
_mm_roundscale_ps
|
|
| difference from rounded value |
|
|
|
|
VREDUCEPD* (V5+DQ...
_mm_reduce_pd
|
VREDUCEPS* (V5+DQ...
_mm_reduce_ps
|
|
| add / sub |
|
|
|
|
ADDSUBPD (S3
_mm_addsub_pd
Sse3.AddSubtract ♯
|
ADDSUBPS (S3
_mm_addsub_ps
Sse3.AddSubtract ♯
|
|
| horizontal add |
|
PHADDD (SS3
_mm_hadd_epi32
Ssse3.HorizontalAdd ♯
|
PHADDW (SS3
_mm_hadd_epi16
Ssse3.HorizontalAdd ♯
PHADDSW (SS3
_mm_hadds_epi16
Ssse3.HorizontalAddSaturate ♯
|
|
HADDPD (S3
_mm_hadd_pd
Sse3.HorizontalAdd ♯
|
HADDPS (S3
_mm_hadd_ps
Sse3.HorizontalAdd ♯
|
|
| horizontal sub |
|
PHSUBD (SS3
_mm_hsub_epi32
Ssse3.HorizontalSubtract ♯
|
PHSUBW (SS3
_mm_hsub_epi16
Ssse3.HorizontalSubtract ♯
PHSUBSW (SS3
_mm_hsubs_epi16
Ssse3.HorizontalSubtractSaturate ♯
|
|
HSUBPD (S3
_mm_hsub_pd
Sse3.HorizontalSubtract ♯
|
HSUBPS (S3
_mm_hsub_ps
Sse3.HorizontalSubtract ♯
|
|
| dot product |
|
|
|
|
DPPD (S4.1
_mm_dp_pd
Sse41.DotProduct ♯
|
DPPS (S4.1
_mm_dp_ps
Sse41.DotProduct ♯
|
|
| multiply and add |
|
|
PMADDWD (S2
_mm_madd_epi16
Sse2.MultiplyAddAdjacent ♯
|
PMADDUBSW (SS3
_mm_maddubs_epi16
Ssse3.MultiplyAddAdjacent ♯
|
|
|
|
| fused multiply and add / sub |
|
|
|
|
VFMADDxxxPD*
(FMA
_mm_fmadd_pd
Fma.MultiplyAdd ♯
VFMSUBxxxPD*
(FMA
_mm_fmsub_pd
Fma.MultiplySubtract ♯
VFMADDSUBxxxPD
(FMA
_mm_fmaddsub_pd
Fma.MultiplyAddSubtract ♯
VFMSUBADDxxxPD
(FMA
_mm_fmsubadd_pd
Fma.MultiplySubtractAdd ♯
VFNMADDxxxPD*
(FMA
_mm_fnmadd_pd
Fma.MultiplyAddNegated ♯
VFNMSUBxxxPD*
(FMA
_mm_fnmsub_pd
Fma.MultiplySubtractNegated ♯
xxx=132/213/231
|
VFMADDxxxPS*
(FMA
_mm_fmadd_ps
Fma.MultiplyAdd ♯
VFMSUBxxxPS*
(FMA
_mm_fmsub_ps
Fma.MultiplySubtract ♯
VFMADDSUBxxxPS
(FMA
_mm_fmaddsub_ps
Fma.MultiplyAddSubtract ♯
VFMSUBADDxxxPS
(FMA
_mm_fmsubadd_ps
Fma.MultiplySubtractAdd ♯
VFNMADDxxxPS*
(FMA
_mm_fnmadd_ps
Fma.MultiplyAddNegated ♯
VFNMSUBxxxPS*
(FMA
_mm_fnmsub_ps
Fma.MultiplySubtractNegated ♯
xxx=132/213/231
|
|
Shuffle instructions do.
Example: Copy the lowest float element to other 3 elements in XMM1.
Unpack instructions do.
Example: Zero extend 8 WORDS in XMM1 to DWORDS in XMM1 (lower 4) and XMM2 (upper 4).
Example: Sign extend 16 BYTES in XMM1 to WORDS in XMM1 (lower 8) and XMM2 (upper 8).
Example (intrinsics):
Sign extend 8 WORDS in __m128i variable words8 to DWORDS in dwords4lo (lower 4) and dwords4hi (upper 4)
If an integer value is positive or zero, it is already the abosoute value. Else, adding 1 after complementing all bits makes the absolute value.
Example (intrinsics): Set abosolute values of 4 DWORDS in __m128i variable dwords4 to dwords4
Floating-Points are not complemented so just clearing sign (the highest) bit makes the absolute value.
Example (intrinsics): Set absolute values of 4 floats in __m128 variable floats4 to floats4
Signed/unsigned makes difference only for the calculation of the upper part. Fot the lower part, the same instruction can be used both for signed and unsigned.
Bitwise operation after getting mask by compararison does.
Example (intrinsics): Compare each signed byte in __m128i variables a, b and set larger one to maxAB
PCMPEQx instruction does.
Example: set -1 to all of the 2 QWORDS / 4 DWORDS / 8 WORDS / 16 BYTES in XMM1.